





An Introduction to Sentiment Analysis using PredicTenor
The multinational Indian conglomerate Adani Group, is taking the heat after the US based Hindenburg Research released a report alleging the former to be involved in fraudulent business practises. Post-release, the report negatively impacted the stock prices of Adani Group. Twitter posts, tracked using the AI-ML live app developed by Cognext, about the Adani group showed a similar trend. The net sentiments about Adani Group hit the rock bottom after the news broke out on 24 January 2023. Five days later, Adani group published a reply, denying all the allegations. However, despite their rebuttal, the sentiments continued to stay negative in the following days; so were the growth in their stock prices.User generated content – such as those from Twitter, Facebook, Google – forms a major informational source, that could be used to understand public sentiments.
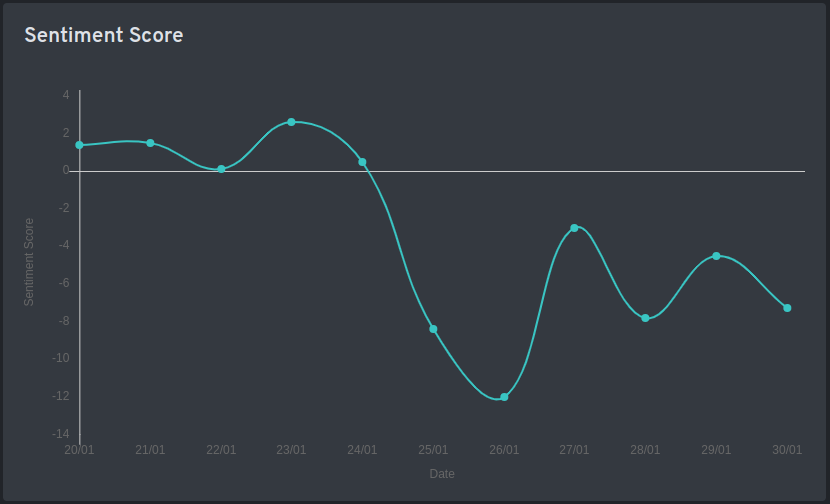 Figure 1: Variation of net sentiments of Adani group from 20 January 2023 to 30 January 2023. Note the dip after 24 and the dip on 29 January 2023, suggesting that the rebuttal published by Adani group wasn't well received to counter the impact of Hindenburg report published on 24th January 2023.
Figure 1: Variation of net sentiments of Adani group from 20 January 2023 to 30 January 2023. Note the dip after 24 and the dip on 29 January 2023, suggesting that the rebuttal published by Adani group wasn't well received to counter the impact of Hindenburg report published on 24th January 2023.
The use of natural language processing in financial institutions is witnessing a surge in adoption, in the backdrop of increasing accessibility to Artificial Intelligence and deep neural networks. A common use case is using sentiment analysis to track its own ‘public perception’ from social media posts like Twitter, Facebook, Google. This a very useful metric, especially in this day and age of FinTechs and digital banks. Another use case for natural language processing is in tracking the ‘sentiment’ of counterparties that it is exposed to – for instance the sentiment of news articles about a borrower, which can be used as an early warning signal. It would be a humanly impossible task to go through all the news articles and social media posts to deduce any actionable insights. There is a need for automated sentiment analysis of texts produced by these financial agents to ease the daily process.
While we have a proprietary Cognext Financial Sentiment Analysis Model (CFSAM), which has been built using a BERT architecture, this post gives a sneak preview into how a social media Sentiment Analysis model can be set up at financial institutions, and give the reader access to a live app, which we have named PredicTenor.
PredicTenor is a live AI app, developed by the CogNext AI-ML team, that makes use of sentiment analysis to determine the public mood about an entity. Sentiment analysis is a machine-learning based natural language processing (NLP) technique to estimate subjective emotions expressed in textual data, and classify them into positive, neutral and negative content. Application of sentiment analysis techniques on user-generated content – like tweets, product reviews, comments etc – makes it a powerful tool to understand trends in public opinion.
A tool combining these features – that is, gathering user-generated content and estimating sentiments – can be used to gather trends that may impact the credit risk of a borrower. For example, public sentiment towards a sector or industry related to the borrower’s domain can be analysed, by looking up the tweets posted about that domain. The brand reputation of the borrower can be gathered and analysed similarly. These inputs will be helpful for the financial institutions to determine the credit risk of their customers.
Furthermore, sentiment analysis of user-generated content can also be used to monitor the reputation index of financial institutions. By analysing user-generated content, like tweets about them, financial institutions can keep a track on the evolution of their reputation. If necessary, they can prepare well ahead of time and adopt mitigative measures to address any issues that may arise. Such a system, therefore, would additionally serve as an early warning system to detect potential issues.
Tracking the social media sentiments over a long period of time, enable organisations to build intelligence on how the extremely chaotic public opinions are evolving around an event. Even real-time estimates on how the public is responding to an event – say a natural disaster or a market event – can be made. These additional inputs can aid financial institutions in their decision-making process in a short-span of time.
However, manually searching for relevant content and analysing the sentiments can be cumbersome. Thanks to APIs and advances in machine-learning based NLP techniques, these processes can be completely automated. Hundreds of thousands of social media content can be analysed in a matter of minutes, which would have otherwise taken days, if not weeks.
Said that, machine-learning based sentiment analysis techniques are subjected to biases and errors in the dataset on which the algorithms were trained. Therefore, the sentiment trends estimated by the algorithm should be used with other data and research methods, to ascertain the public mood.
In this article, a simple method to efficiently scrape user-generated content from Twitter – a popular social media platform will be demonstrated. An efficient model to estimate the sentiments of this content, and to accurately compute the sentiment score, is also presented. Various factors like – confidence of estimation, the social impact of a content, how influential the content creator is, etc, which are incorporated to determine the sentiment score, will also be discussed in further sections.
 Figure 2: The user interface of PredicTenor is simple and intuitive even for a layperson.
Figure 2: The user interface of PredicTenor is simple and intuitive even for a layperson.
PredicTenor takes a search string as input and queries the Twitter Search API for the hundred most-relevant tweets in the past seven days containing the search string, and the hashtag. The user can also opt for gathering all tweets, matching the search string, in the past seven days by disabling the ‘Relevant Tweets’ option. The former option is optimal to get a ballpark sentiment trend in a short-time, and the latter is suited for accuracy focussed trends. By default, retweets will be ignored and only the original tweet will be considered. There is also an option to exclude tweets originating from a list of Twitter handles. This option can be used to eliminate the inclusion of tweets from official accounts of the organisation - which will typically be positive – thus skewing the overall sentiment score to positive side, deflecting from the actual public opinion. Currently, only the content identified as English is collected. However, it is possible to scrape content in all languages.
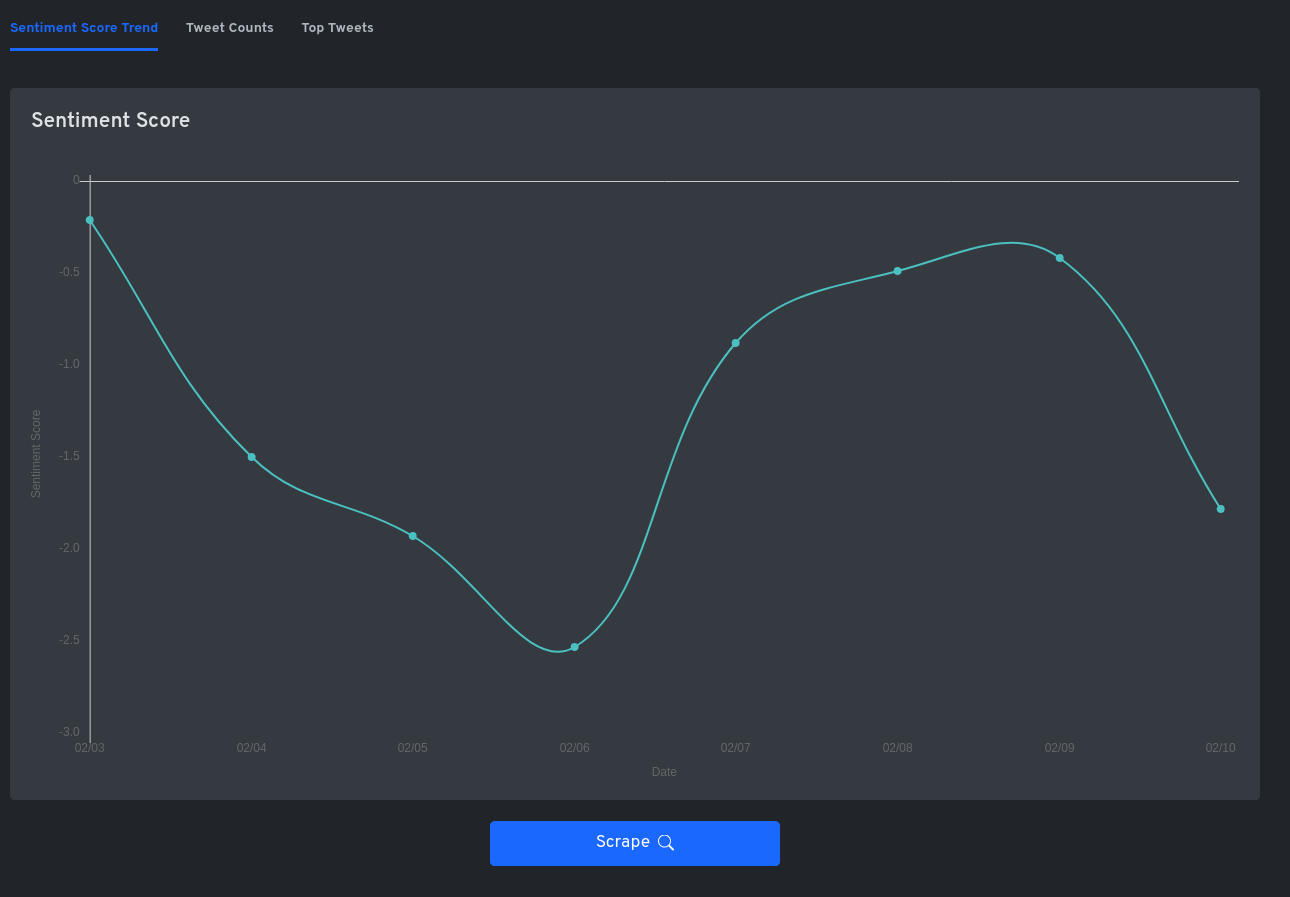 Figure 3: The first view shows the sentiment trends in the past seven days.
Figure 3: The first view shows the sentiment trends in the past seven days.
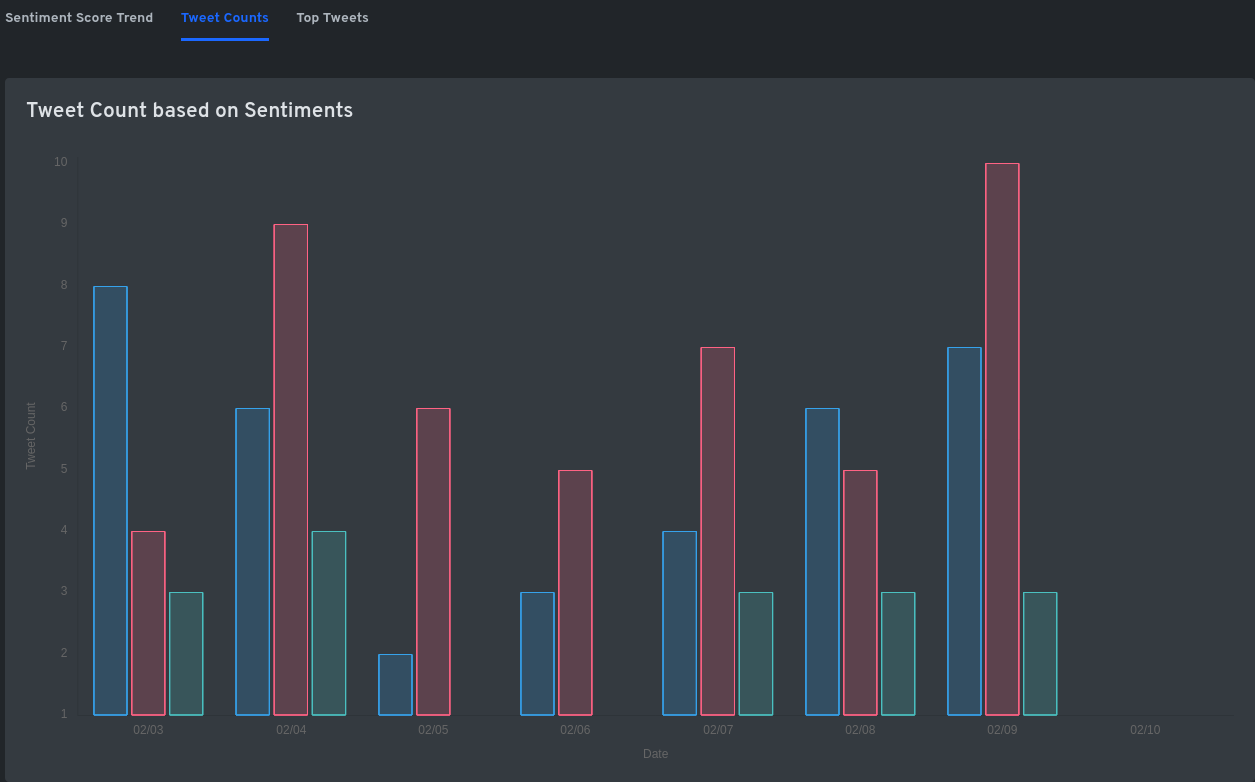 Figure 4: The second view gives an idea of the tweet volume in the past seven days.
Figure 4: The second view gives an idea of the tweet volume in the past seven days.
Once the scraping is completed – which is linearly dependent on the tweet volume – the sentiment estimation and determination of day-wise sentiment score is done. For simplicity, only the English language content is supported, even though sentiment analysis in multiple languages is supported by the backend. The results are presented in three different views, which helps the decision-makers to understand the sentiment trends, and the causation agents. The first view shows the variation of sentiment score over days. The number of days can vary according to the selection of ‘Relevant Tweets’ option. If the option is disabled, it would show the variation over the past seven days. The second view shows the day-wise count of positive, neutral and negative tweets. This will give an idea of the volume of tweets, and additionally, how the public emoted on a given day pointing towards a critical event, that needs attention. This chart must be read with the first chart, to get a confirmation of findings from the first view. The last view shows the top five negative tweets that contributed to the overall sentiment score for a given day. This provides an insight into the major issues that have contributed to the sentiment trend for that day.
Behind the scenes, two APIs work hand-in-glove to enable the features of PredicTenor. One for scraping the tweets from the Twitter Search API, and the other to analyse sentiments of the scraped tweets. Requests, a lightweight Python library, was used to build the Tweet scraping engine with bare minimum requirements, avoiding bloats. FastAPI was chosen to build the API endpoints, considering factors like speed, scalability, and ease of development. Other popular frameworks like Django and Flask were considered, but were dropped in favour of FastAPI owing to its suitability to the project requirements. FastAPI, as the name suggests, is one of the fastest web frameworks available in Python. It is a common choice for deployment of AI apps. TweetNLP is a powerful Python library that was specifically developed for processing Twitter content. It is built on top of pytorch and utilises GPU potential using CUDA, and is commonly used for sentiment analysis of Tweets. A roBERTa based model was used to develop the underlying text-analytics model of TweetNLP. Trained with approximately 124 million tweets, this library is a result of academia-industry collaboration, under the leadership of a group of NLP researchers from Cardiff University, Cambridge University and Granada University. A detailed note on determination of sentiment score is detailed in a further section. Bootstrap v5 based template was chosen to develop the front-end, owing to its features like responsiveness and browser compatibility, enabling quick development of a responsive and professional looking front-end. Chart.js, an open-source JavaScript library, was used to visualise data in the front-end. It is a powerful, lightweight library which is highly customisable and easy to implement. It supports a variety of data visualisations, and compatible with almost all the popular browsers.
The sentiment estimates by TweetNLP comes with a probability too, which signifies the estimation confidence. If the estimation probabilities of two sentiments are too close to each other, there arises a need to resolve this ambiguity. Two cases, as listed below, are identified and resolved.
1. Weak neutrals: If the estimation probability of a neutral sentiment is closer to either positive or negative within an absolute tolerance of 0.01, the neutral sentiment is corrected as either positive or negative, whichever is closer.
2. Ambiguous positive and negatives: If the estimation probabilities of positive and negative sentiments are closer within an absolute tolerance of 0.01, they are corrected as neutral.
Sentiment labels are then mapped to sentiment values (S) as follows,
With the sentiments estimated for individual tweets, it is important to aggregate the sentiments for a given day in a systematic and robust manner, to understand the sentiment trends. One contributing factor would be the probability of estimation (C). The impact of a tweet (E) must also be taken into consideration, e.g., a tweet with greater engagements will be more impactful than a tweet with zero or low engagement. Factoring in all these parameters, the Sentiment Score Ssen is computed as, Ssen = f (S, C, E)
PredicTenor, because it is built on top of Twitter Standard Search API, have only access to twitter content up to seven days old. Additionally, the rate-limits set for the freely available Standard API endpoint slows down the scraping process, especially when the Tweet volumes are huge. This highly limits PredicTenor’s potential as a long-term sentiment tracker, as in case of reputation index tracker, or real-time generation of results, as in case of early warning systems. However, these issues can be overcome by utilising Enterprise/Premium solutions offered by Twitter. The existing text-analytics model was used as provided by the TweetNLP developers. The text-analytics model can be fine-tuned for the requirements demanded by the specific domains of credit risk analysis, reputation index tracking and early warning systems.
The existing app is limited to bare minimum features to demonstrate the potential of the tool. However, more feature additions are in the pipeline to extend the functionality, to improve the performance and to provide more and better insights. Some planned functional features are listed below:
1. Add Irony detection, Named Entity Recognition (NER), Emotion detection.
2. Geographical fencing: Scrape tweets from a specific geographical location(s).
3. Context-Aware searches: Scrape tweets from a specific business domain.
4. Multilanguage support: Support for languages other than English.
5. Issue identification: Programmatically identify the most discussed issue, or contributing issue.
7. Heatmaps: Generate a heatmap of negative and positive tweets.
8. Identify potential influencers
In addition to the above features, various performance improvements, like parallelisation of processes, and code level optimisations will be brought in to reduce the latency in generating the results.
Please reach out to us in case you need any further information: info@cognext.ai